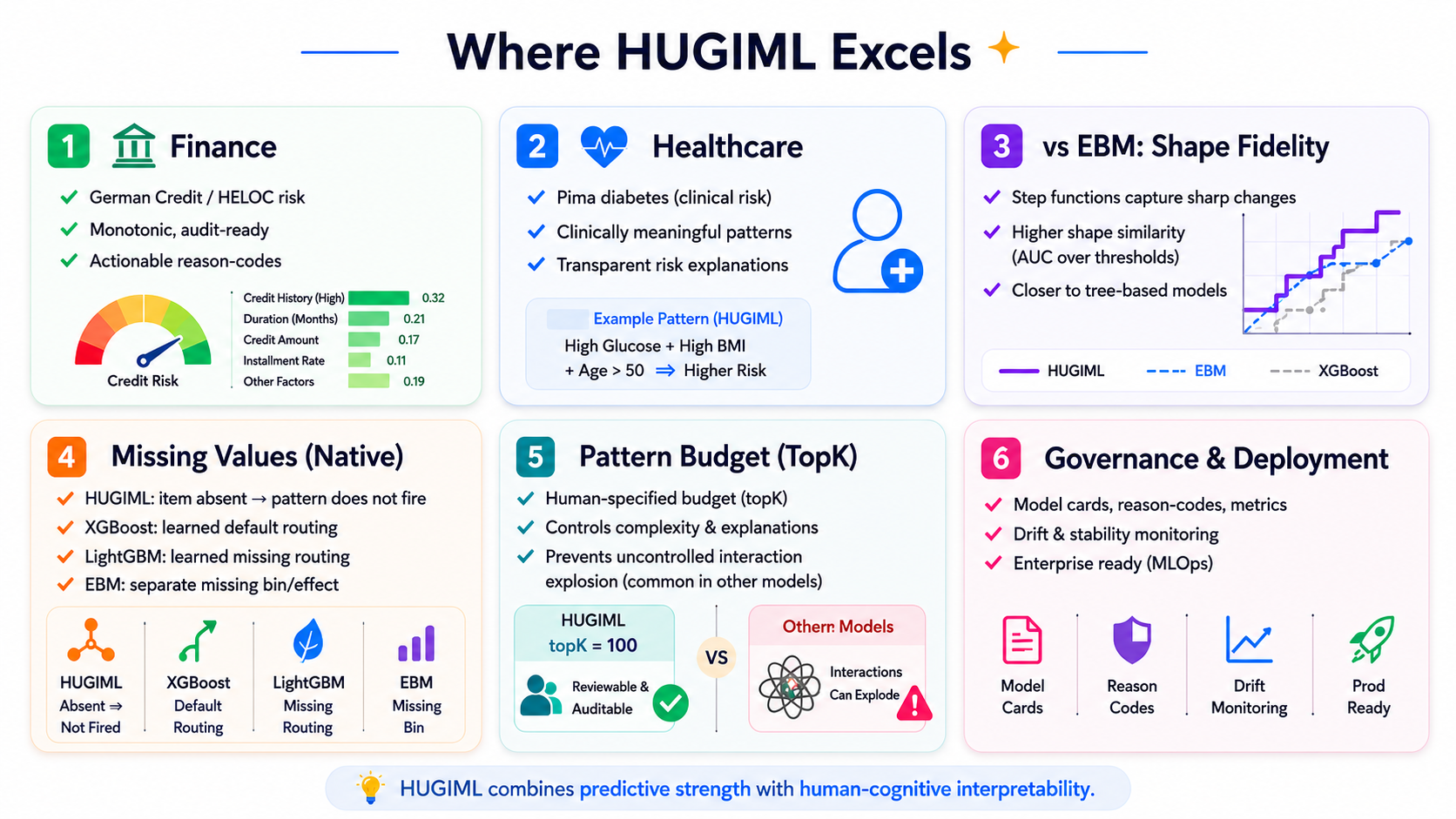
Core concepts
HUG-IML process
HUG-IML extracts High Utility Gain patterns from labelled tabular data, transforms every row into a binary pattern-presence matrix, and trains an interpretable downstream classifier on that matrix.
The practical modeling sequence is:
Detect or provide feature types: integer, float, and categorical.
Discretize numerical columns into bins.
Build transactions from observed feature-bin/category items.
Mine top High Utility Gain patterns with information-gain filtering.
Transform samples into a sparse binary matrix indicating which patterns fire.
Fit the downstream estimator, logistic regression by default.
Expose pattern labels, support, utility, information gain, coefficients, and local active-pattern explanations.
Pattern anatomy
A learned pattern is readable because it is expressed in the vocabulary of the input data:
glucose=[157.1,177.3) AND bmi=[31.8,39.1) coef=+1.41 support=0.067
checking_status=no_checking coef=+1.12 support=0.390
Useful fields include:
Field |
Meaning |
|---|---|
|
Human-readable feature interval/category combination. |
|
Fraction of training samples where the pattern is active. |
|
Pattern utility score used during mining. |
|
Supervised filtering signal for target relevance. |
|
Downstream classifier contribution, when available. |
Key hyperparameters
Parameter |
Role |
Typical starting point |
|---|---|---|
|
Numerical bin count, or upper bound when adaptive binning is enabled. |
|
|
Maximum pattern length. |
|
|
Minimum information gain threshold. |
|
|
Maximum number of retained patterns. In the native 1.1.x path this budget is applied inside mining, so it is both an interpretability cap and a performance control. |
|
|
Selects per-feature bin resolution with supervised information gain. |
|
|
Optionally selects adaptive bin counts on a deterministic stratified row sample before full-data training. |
|
Missing values
Numerical NaN and infinite values are treated as not observed. The corresponding item is absent from the transaction, so patterns requiring that feature do not fire for that row. This avoids fabricating values through mean or median imputation.
When missingness is itself meaningful, add explicit binary indicators before fitting:
X_aug = X.copy()
for col in X.columns:
if X[col].isna().mean() > 0.05:
X_aug[f"{col}__MISSING"] = X[col].isna().astype(int)
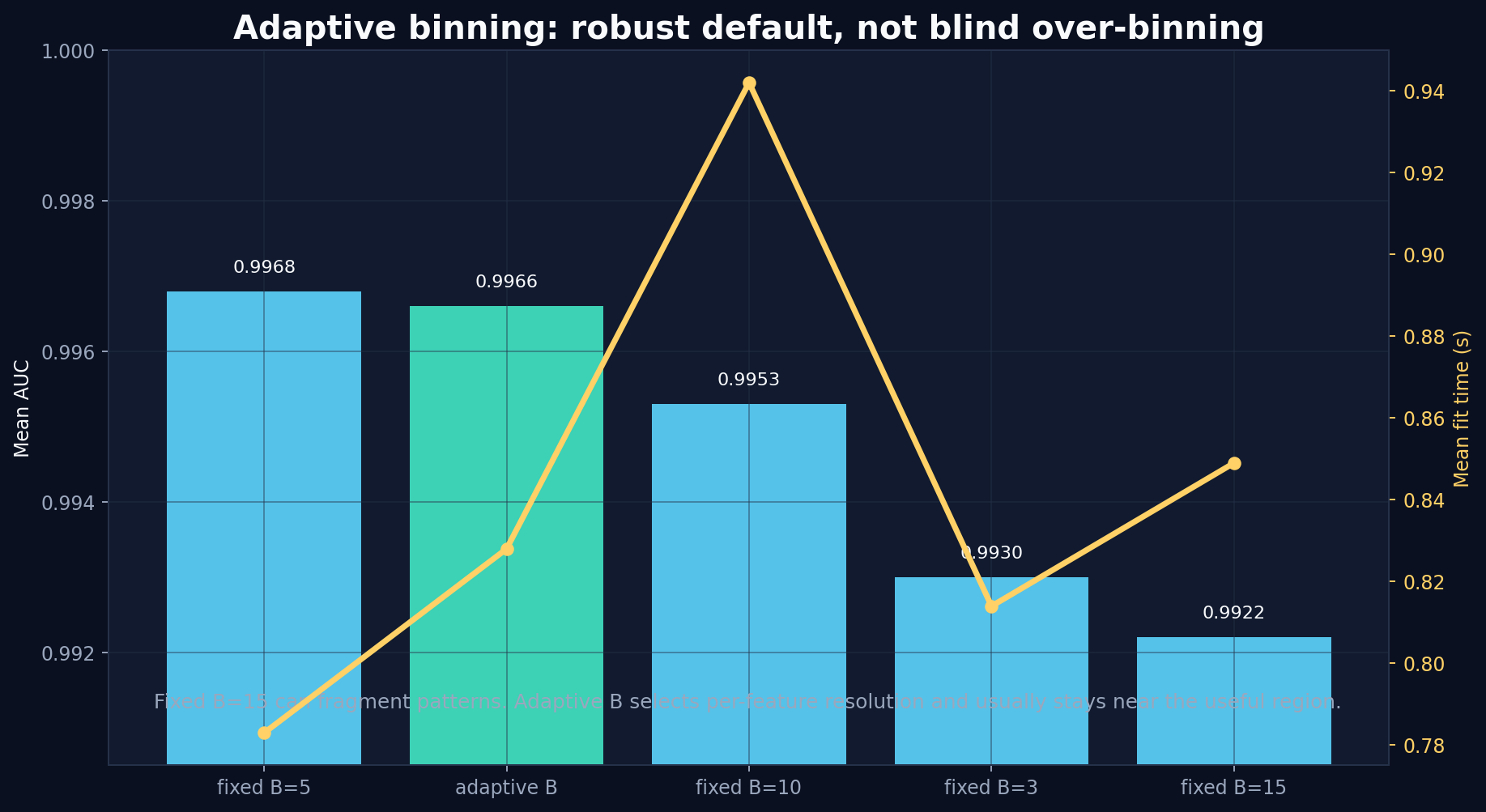
Adaptive binning
Adaptive binning selects a bin count per numerical feature by evaluating candidate B values using supervised information gain and stopping when marginal gains become small. On larger datasets, adaptive_binning_sample_frac can run the bin-count search on a deterministic stratified row sample; the selected edges are then applied to the full training data.
from hugiml import HUGIMLClassifier
clf = HUGIMLClassifier(
adaptive_binning=True,
b_candidates=[2, 3, 5, 7, 10, 15],
min_marginal_gain_ratio=0.02,
adaptive_binning_sample_frac=0.20,
L=2,
G=1e-4,
)
Performance and mining behavior
The 1.1.x native path keeps the modeling interface stable but changes where work is bounded internally. The effective topK value is passed into the native mining stage before candidate retention, rather than being treated only as a post-processing cap. This is closer to the original HUGIML Java implementation and is important for larger datasets because fewer non-final candidates need to be materialized.
For L=1 fits, the native hot path fuses transaction preparation, singleton pattern mining, information-gain filtering, top-K retention, and sparse matrix construction. This hot path supports adaptive binning without first materializing a separate binned matrix, which is the recommended route for large adaptive singleton workflows. Set use_hotpath=False only when comparing against the older three-stage path for debugging or benchmarking.
Transaction construction is performed in row-stripe chunks on the non-fused path, and materialized native transactions now store compact item ids with shared item-level utility lookup. The resulting model is intended to match the previous transaction semantics while reducing repeated utility storage and making memory use less bursty. This is most useful for wide data, large batches, and cross-validation loops.
For interaction mining, structured constraints are applied exactly. In v1.1.17, native mining includes dedicated hot paths for L=1, L=2, and L=3 before falling back to the generic bounded miner for higher orders. EUCS and pair-cache pruning are enabled only after workload gates confirm that they are likely to be useful. Prefer controlling complexity with L, G, and topK first; see Native mining pruning controls for hot-path behavior, EUCS parameters, and native pruning guidance.
Operational stability controls
Use n_jobs=-1 to allow the native backend to use all available OpenMP threads. The adaptive bin-selection and bin-code application stages can use this parallelism before the main mining step, so it benefits adaptive workflows as well as the fused L=1 path.
max_mining_seconds is a wall-clock budget for the native mining stage; max_fit_seconds remains a backward-compatible alias. If the budget or memory pressure prevents the full configuration from completing, HUGIML attempts safer fallback configurations, records the degraded outcome in fit_metadata_.degraded, and keeps a compact attempt log in mining_audit_log_. Inspect fit_metadata_ and get_mining_audit_log() after fitting to review pattern counts, stage timings, memory estimates, OpenMP thread count, timeout status, and whether a fallback was used.
Constant and zero-utility columns
A column that is constant after preprocessing cannot contribute useful pattern utility. The estimator may emit HUGIMLConvergenceWarning for these columns during prepareXy or fit. This warning is expected: the column is ignored for pattern mining, while the rest of the dataset continues to train normally. In production pipelines, drop known constant columns before fitting if you want a quieter log.