Benchmarks
The benchmark runner provides reproducible cross-validation comparisons for HUGIML and common tabular baselines. It supports three practical paths: predefined datasets, user-supplied datasets, and optional inner-CV tuning.
Install the benchmark optional dependencies before using the runner:
pip install "hugiml-core[benchmarks]"
The benchmark extra includes the statsmodels dependency used by the expanded
real-world experiment panel. Root-level experiments/ runners are included
in the source distribution and source checkout; they are not installed as
wheel package modules.
OpenML-CC18 benchmark
The repository also includes an OpenML-CC18 workflow covering 36 classification datasets. It uses each OpenML task’s official train/test indices for the outer evaluation and keeps preprocessing and optional parameter selection inside the corresponding training partition. This preserves the benchmark protocol while keeping the comparison reproducible from an offline dataset cache.
The workflow consists of:
experiments/benchmark/download_openml_cc18_datasets.pyfor downloading and validating the task data and split manifests;experiments/benchmark/run_openml_cc18_offline_benchmark.pyfor resumable task/model evaluation and static dashboard assembly; andexperiments/benchmark/openml_cc18_benchmarkREADME.mdfor operational commands, cache layout, model selection, and result-file details.
The generated openml_cc18_benchmark_dashboard.html summarizes paired AUC,
runtime, model inspection units, instance inspection effort, task coverage,
configuration details, and dataset-level results. HUGIML is compared with the
selected available baselines under the same outer task splits. The workflow is
resumable: completed task/model pairs are retained, while incomplete split
attempts can be evaluated again without duplicating completed result rows.
You can run the benchmark module directly or use the installed console script:
python -m hugiml.benchmarks.runner --datasets breast_cancer adult credit --output benchmarks/results/
hugiml-bench --datasets breast_cancer --output results/
Compared models
The runner compares HUGIML with a compact set of tabular baselines when their optional packages are installed:
HUG-IML
EBM
XGBoost
LightGBM
RandomForest
LogisticReg
RuleFit
GAM
Optional baselines that are not installed are skipped, so a benchmark run can still complete in lightweight environments.
Predefined datasets
Use --datasets for the packaged benchmark datasets. The current predefined
set is:
breast_canceradultcredit
Examples:
# Run all predefined datasets
hugiml-bench --output benchmarks/results/
# Run a selected subset
hugiml-bench --datasets breast_cancer adult --output benchmarks/results/
# Restrict the comparison to selected models
hugiml-bench --datasets breast_cancer --models HUG-IML LightGBM RandomForest
Custom datasets
Use --data and --target for a user-supplied binary classification
problem. CSV, TSV, Excel, and Parquet files are supported.
hugiml-bench \
--data data/customer_risk.csv \
--target default_flag \
--dataset-name customer_risk \
--output benchmarks/results/customer_risk
Useful custom-dataset options:
--id-columnexcludes an identifier column from modeling.--exclude-columnsexcludes a comma-separated list of columns.--positive-labelsets the positive class when the target is not already encoded as 0/1.--n-splitscontrols the outer stratified CV folds.--modelsrestricts the model set.
The runner preserves pandas categorical metadata for HUGIML. Non-HUGIML baselines are wrapped in a fold-fitted one-hot encoder plus numeric imputer so benchmark preprocessing stays inside each validation split. Fully missing columns are removed before model comparison. For production modeling, keep benchmark preprocessing separate from the validated feature pipeline used by the deployed model.
Tuned benchmarks
Add --tune to run inner-CV hyperparameter tuning inside each outer fold.
For HUGIML, eligible adaptive-binning grids use the fast tuning path exposed by
HUGIMLClassifierNative.tune. Other estimators use the shared benchmark grids
from hugiml.hyperparameter_configs when available, and models without a
stable tuning grid remain on their baseline configuration.
# Tune HUGIML and available baselines on a predefined dataset
hugiml-bench --datasets breast_cancer --tune --n-splits 5 --inner-splits 3
# Tune on a custom dataset
hugiml-bench \
--data data/customer_risk.csv \
--target default_flag \
--tune \
--n-splits 5 \
--inner-splits 3 \
--output benchmarks/results/customer_risk_tuned
Tuning increases runtime because each outer fold runs an inner validation loop.
Use a smaller model set with --models when you need a focused comparison.
Programmatic use
The benchmark functions can also be imported from Python:
from hugiml.benchmarks.runner import run_benchmark, run_custom_benchmark
built_in = run_benchmark(
"breast_cancer",
n_splits=5,
output_dir="benchmarks/results",
tune=True,
inner_splits=3,
models=["HUG-IML", "LightGBM", "RandomForest"],
)
custom = run_custom_benchmark(
data="data/customer_risk.csv",
target="default_flag",
dataset_name="customer_risk",
output_dir="benchmarks/results/customer_risk",
tune=False,
)
Outputs
Each dataset run writes per-fold metrics and summary artifacts when
--output or output_dir is provided:
<dataset>_results.csvwith fold-level metrics.<dataset>_summary.jsonwith mean and standard deviation summaries.full_report.csvwhen multiple datasets are run from the CLI.
Reported metrics include accuracy, balanced accuracy, ROC-AUC, average
precision, F1, Brier score, fit time, prediction time, and tuning time when
--tune is enabled. Tuned runs also record the selected parameter summary and
best inner-CV score where available.
Benchmark visuals
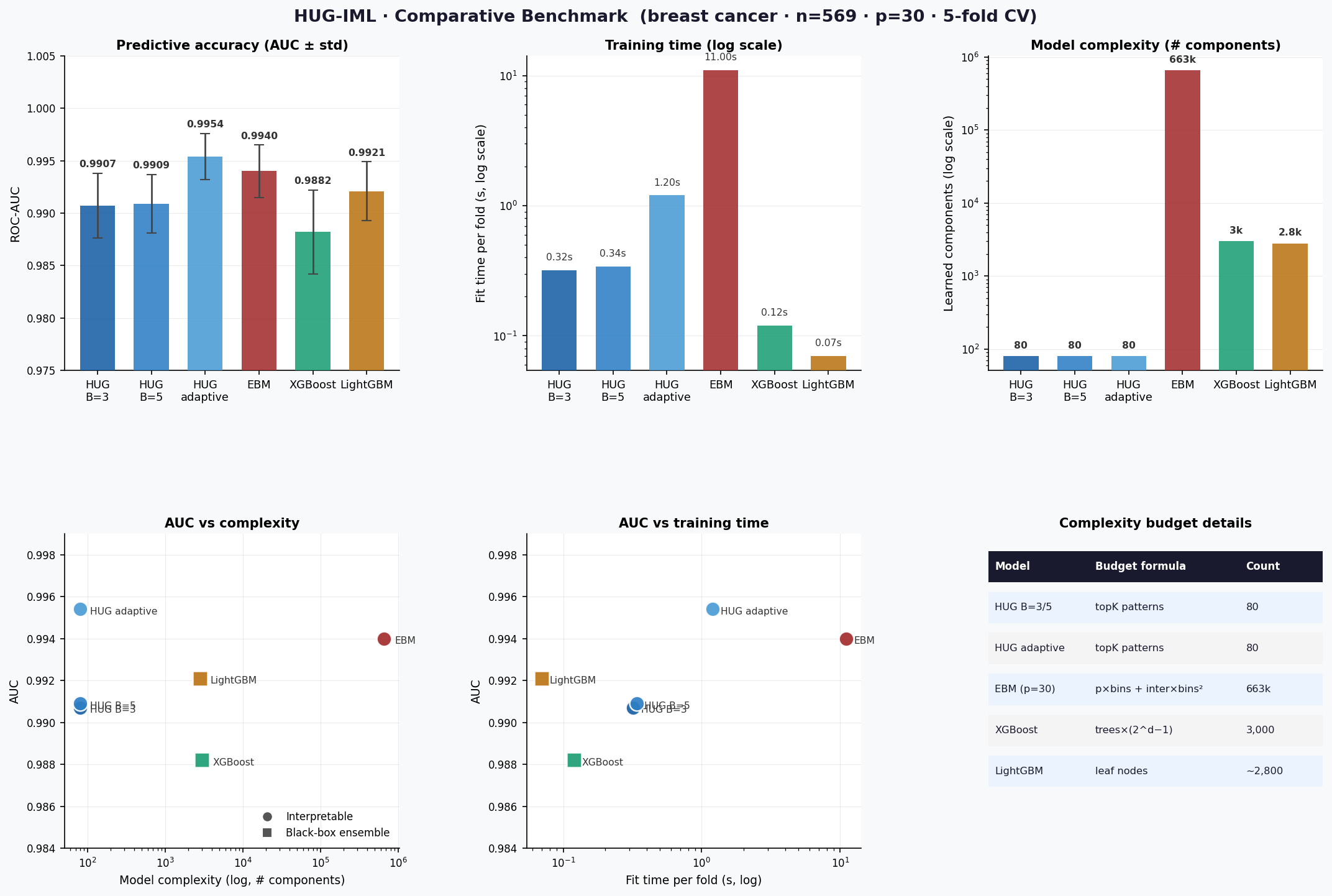
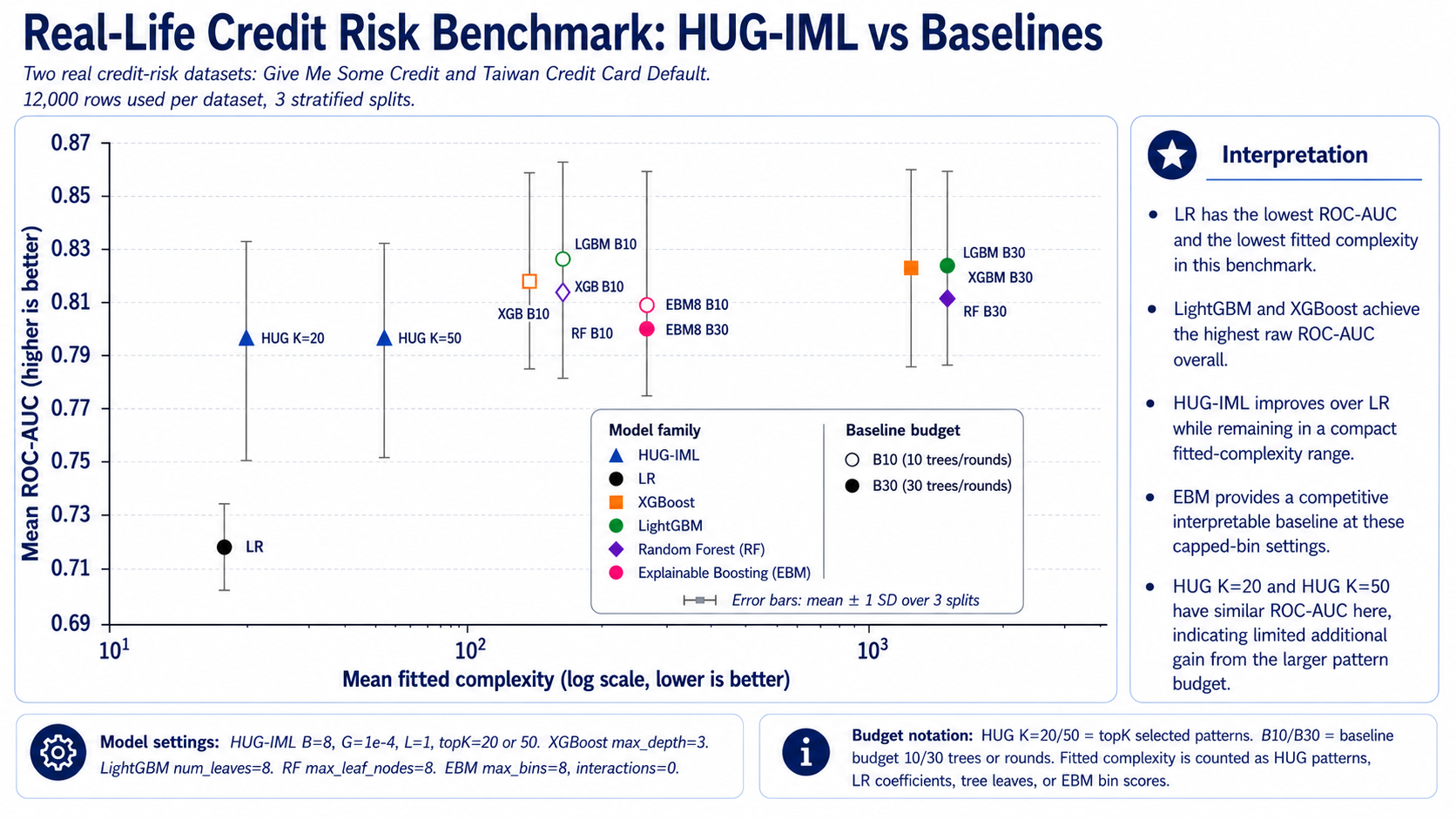
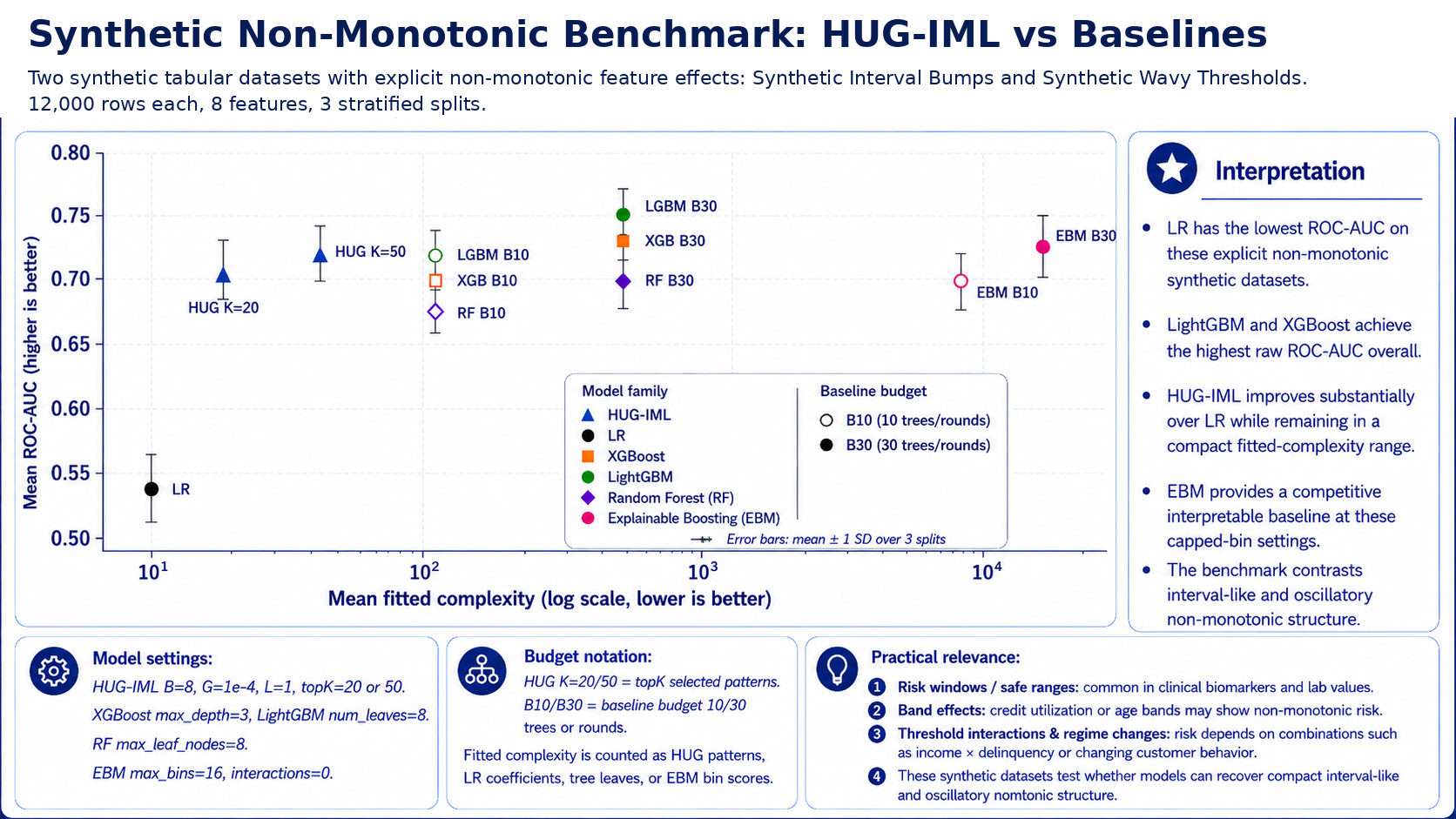
Missing-value robustness
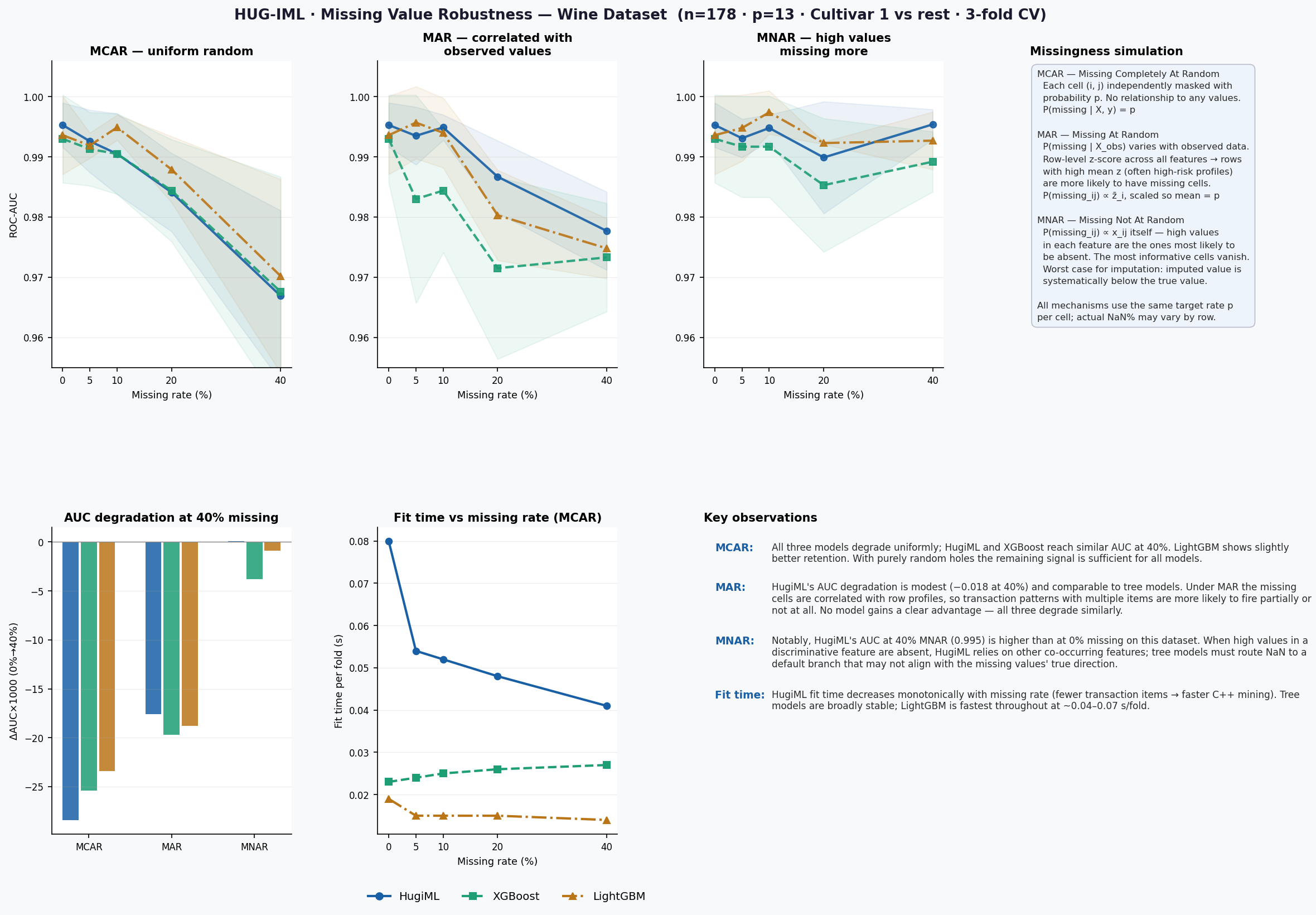
Interpretation guidance
The benchmark suite should be read as a trade-off analysis, not as a universal
ranking. Boosted tree models can deliver high raw predictive scores, while
HUGIML emphasizes compact pattern-level explanations, governance artifacts, and
auditable behavior. For larger datasets, start with L=1 and a bounded
topK to keep mining and audit complexity manageable. The fused native
L=1 path is the preferred benchmark setting for large adaptive-binning runs
because it avoids intermediate adaptive binned-matrix materialization.
Reproducibility notes
Record dataset versions, preprocessing, train/test splits, and random seeds.
Compare both mean and standard deviation across folds.
Include complexity measures such as number of patterns, active patterns per prediction, fitted-feature count, and fit time.
Use statistical tests or confidence intervals when differences are small.